【徹底解説】ElevenLabs (イレブンラボ) とは?AI音声合成の機能・料金・使い方を完全ガイド
AI / elevenlabs
【この記事にはPRを含む場合があります】
近年、YouTube動画やコンテンツ制作においてAI音声生成ツールは不可欠な存在となりつつあります。中でも、ElevenLabs (イレブンラボ) は、その高いクオリティと表現力で注目を集めるAI音声プラットフォームです。テキストをまるで人間が話しているかのような自然な音声に変換し、コンテンツクリエイターや開発者、企業など幅広いユーザーに活用されています。
この記事では、ElevenLabsとはどのようなツールなのか、その豊富な機能や特徴、料金プラン、商用利用の可否、そして具体的な使い方まで、徹底的に解説していきます。
あわせて読みたい

- ElevenLabsとは?
- ElevenLabsで何ができる?その特徴と機能
- テキスト読み上げ (Text to Speech)
- オーディオタグ (Audio Tags) による感情表現とディレクション
- マルチスピーカーダイアログ (Multi-speaker Dialogue)
- 多言語対応
- ボイスクローン (Voice Cloning) とボイスデザイン (Voice Design)
- ボイスチェンジャー (Voice Changer)
- ボイスアイソレーター (Voice Isolator)
- サウンドエフェクト (Sound Effects)
- スタジオ (Studio) 機能
- ダビング (Dubbing)
- 料金プラン、商用利用、対応デバイス
- ElevenLabsの使い方
- 実際にElevenLabsを使ってみたレビュー
- AI音声技術が切り拓く新たなコンテンツ制作の未来
ElevenLabsとは?
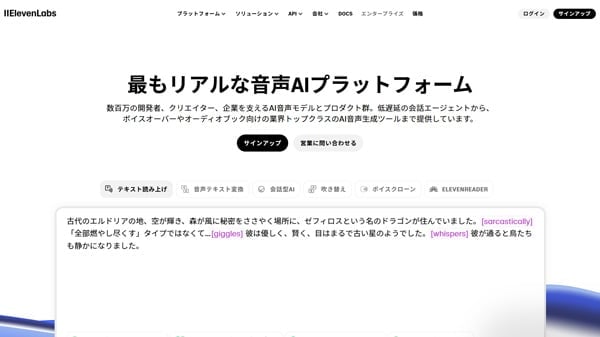
(出典:ElevenLabs)
ElevenLabs (イレブンラボ) は、最先端のAI音声合成技術 を提供するプラットフォームです。単にテキストを読み上げるだけでなく、感情やニュアンスを込めた、非常に表現力豊かなAI音声 を生成できるのが最大の特徴です。
特に、2025年6月8日にアルファ版がリリースされた最新モデルの Eleven v3 (V3) は、「最も表現力豊か」とされており、その自然な音声と多様な表現力が注目を集めています。ElevenLabsは、低遅延の会話型AIエージェントから、ボイスオーバーやオーディオブック向けのAI音声生成まで、幅広い用途で利用されています。
ElevenLabsで何ができる?その特徴と機能
ElevenLabsは、多岐にわたる機能と高い表現力で、様々な音声コンテンツ制作を強力にサポートします。
テキスト読み上げ (Text to Speech)
入力したテキストを自然なAI音声で読み上げます。特にV3モデルでは、テキストの理解度が深まり、より日本語らしいニュアンスやリズム、抑揚の向上が謳われています。
オーディオタグ (Audio Tags) による感情表現とディレクション
テキスト内に特定のオーディオタグ (例: [LAUGHS], [WHISPER], [SARCASTIC], [EXCITED]) を書き込むことで、笑い声やささやき声、皮肉なトーン、興奮した声など、非言語的なニュアンスや感情 をAIに指示できます。これにより、単なる読み上げにとどまらず、まるで役者がパフォーマンスを演じるかのようなダイナミックな音声生成が可能です。自動でオーディオタグを付与する「Enhance (alpha)」機能もあります。
マルチスピーカーダイアログ (Multi-speaker Dialogue)
複数の話者が登場する会話を自然に生成できます。例えば、相槌の打ち方や話の割り込みなども、よりリアルに再現しやすくなりました。
多言語対応
日本語を含む70以上の言語 に対応しており、多言語でのコンテンツ制作に役立ちます。
ボイスクローン (Voice Cloning) とボイスデザイン (Voice Design)
自身の声や特定のキャラクターの声を複製して利用できるボイスクローン機能を提供します。手軽に利用できるインスタントボイスクローン (IVC) と、高品質なプロフェッショナルボイスクローン (PVC) があります。また、テキストプロンプトで声のイメージを記述してオリジナルのAI音声を作成する「ボイスデザイン」機能 も利用できます。
ボイスチェンジャー (Voice Changer)
既存のオーディオファイルを別のAI音声に変換する「スピーチ・トゥ・スピーチ」機能です。自身の声で演技を行い、それをAI音声に適用することで、より感情豊かな表現が可能です。
ボイスアイソレーター (Voice Isolator)
音声ファイルからバックグラウンドノイズを除去し、クリアな声だけを抽出する機能です。
サウンドエフェクト (Sound Effects)
テキストプロンプトで様々な効果音 (例: 猫の鳴き声、拍手、爆発音) を生成できます。
スタジオ (Studio) 機能
長尺のテキストコンテンツを音声化するのに適しており、オーディオブックの作成 や、YouTube動画のボイスオーバー などに活用できます。
ダビング (Dubbing)
動画の音声を他言語に翻訳・吹き替える機能です。元の話者の声を保ちながら多言語対応できるため、コンテンツの国際展開に非常に強力なツールとなります。

料金プラン、商用利用、対応デバイス
ElevenLabsの料金プランは、利用者のニーズに合わせて様々なレベルが用意されています。年間払いを選択すると、2ヶ月分が無料になる特典があります。
利用料金とプランの概要
| プラン名 | 対象ユーザー | 月額料金 (月払い) | クレジット/利用時間目安 (月間) | 主な機能/特徴 | 補足事項 |
|---|---|---|---|---|---|
| 無料 (Free) | 最先端のAIオーディオを試したい個人向け | $0 | 10,000クレジット/月高品質テキスト読み上げ 10分会話型AI 15分(20,000文字相当) | テキスト読み上げ、音声テキスト変換、会話型AI、スタジオ、吹き替え、APIアクセス | 帰属表示が必要で、商業ライセンスは含まれません |
| スターター (Starter) | AIオーディオでプロジェクトを作成する趣味人向け | $5 | 30,000クレジット/月高品質テキスト読み上げ 30分会話型AI 50分(60,000文字相当) | 無料プランの全機能に加え、商業ライセンス、インスタントボイスクローン、スタジオでの20プロジェクト、ダビングスタジオが利用可能 | – |
| クリエイター (Creator) | グローバルな視聴者向けにプレミアムコンテンツを作成するクリエイター向け | $22 (初月は$11) | 100,000クレジット/月高品質テキスト読み上げ 100分会話型AI 250分(200,000文字相当) | スタータープランの全機能に加え、プロフェッショナルボイスクローン、追加クレジットの使用量に基づく請求、より高品質なオーディオ192 kbpsでの出力 | 追加クレジットは1,000文字あたり$0.15 |
| プロ (Pro) | コンテンツ制作を加速するクリエイター向け | $99 | 500,000クレジット/月高品質テキスト読み上げ 500分会話型AI 1,100分(1,000,000文字相当) | クリエイタープランの全機能に加え、API経由での44.1kHz PCMオーディオ出力 | 追加クレジットは1,000文字あたり$0.12 |
| スケール (Scale) | スタートアップや出版社向け | $330 | 2,000,000クレジット/月高品質テキスト読み上げ 2,000分会話型AI 3,600分(4,000,000文字相当) | プロプランの全機能に加え、マルチシートワークスペース (+3席) | 追加クレジットは1,000文字あたり$0.09 |
| ビジネス (Business) | 急成長するスタートアップや出版社向け | $1,320 | 11,000,000クレジット/月高品質テキスト読み上げ 11,000分会話型AI 13,750分(22,000,000文字相当) | スケールプランの全機能に加え、1分あたり5セント以下の低遅延TTS、3つのプロフェッショナルボイスクローン | 追加クレジットは1,000文字あたり$0.06 |
| エンタープライズ (Enterprise) | ボリュームに応じた割引やカスタム条件が必要な企業向け | カスタム価格 | カスタムクレジット数とシート数 | ビジネスプランの全機能に加え、DPA/SLAsに関するカスタム条件と保証、HIPAA顧客向けのBAAs、カスタムSSO、より多くのシートと声、無制限の同時実行制限、ElevenStudiosの完全管理ダビング、大規模な割引価格、優先サポート | – |
一般的な注意点:
- 年間払い: いずれのプランも年間払いを選択すると、2ヶ月分が無料になります。
- クレジット換算: V1 English、V1 Multilingual、V2 Multilingualモデルでは1文字が1クレジットに相当します。V2 Flash/Turbo EnglishおよびV2.5 Flash/Turbo Multilingualモデルでは割引が適用され、1文字あたり0.5から1クレジットの範囲で支払うことになります(正確な価格はプランに依存します)。
- サブスクリプションの管理: 有料サブスクリプションを一時停止することはできませんが、キャンセルすると現在の請求サイクルの終了時にアカウントが無料プランに移行されます。
- 支払い方法: クレジットカード、Apple Pay、Google Pay
- 税金: 表示されている価格には、すべての税金、課徴金、関税は含まれていません。
商用利用について
ElevenLabsは「開発者、クリエイター、企業を支援する」プラットフォームとして紹介されており、オーディオブックや動画のボイスオーバー、リアルタイム顧客サポート、インタラクティブNPCなど、ビジネスやコンテンツ制作での活用事例 が多数挙げられています。無料版ではクレジット表記が必要なケースがある旨の記載があり、有料プランでは商用利用が前提となっていると考えられます。詳細は公式の利用規約を確認することをおすすめします。
利用可能デバイス
ElevenLabsは、ウェブブラウザ からアクセスして利用できます。また、AndroidおよびiOS向けのモバイルアプリ も提供されています。これにより、場所を選ばずにAI音声生成を行うことが可能です。
> Google Playストア「ElevenReader: Text to Speech」ダウンロードページはこちら(Android用)
> Google Playストア「ElevenLabs: AI Voice Generator」ダウンロードページはこちら(Android用)
> AppStore「ElevenReader: Text to Speech」ダウンロードページはこちら(iPhone用/iPad用)
> AppStore「ElevenLabs: AI Voice Generator」ダウンロードページはこちら(iPhone用/iPad用)
あわせて読みたい

ElevenLabsの使い方
ElevenLabsの使い方は非常に直感的です。ここでは、基本的なサインアップから音声生成、応用的な機能までを解説します。
サインアップとログイン
- ElevenLabsのウェブサイト (elevenlabs.io) にアクセスします。

- Googleアカウントなどで登録・ログイン できます。メールアドレスでの登録も可能ですが、私は認証で問題が発生したため、Googleアカウントでログインしました。
Googleアカウントからログインの場合は初回でもログインから直接ログインが可能でした。
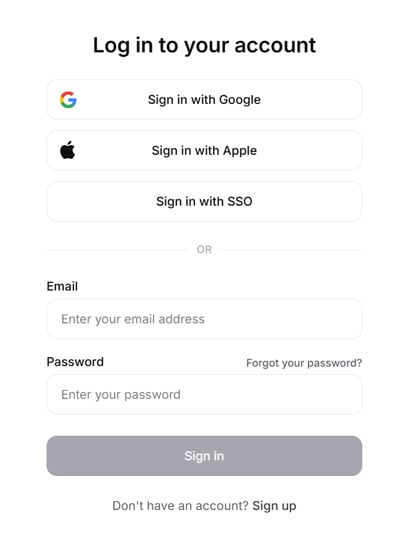
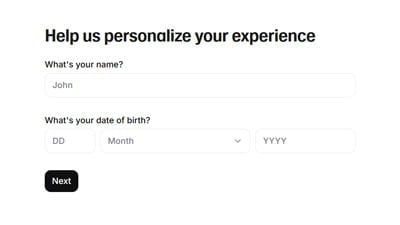
- 初回ログイン時には、UIスタイル、名前、生年月日、利用目的などの情報入力が必要です。
基本的な音声生成 (Text to Speech)
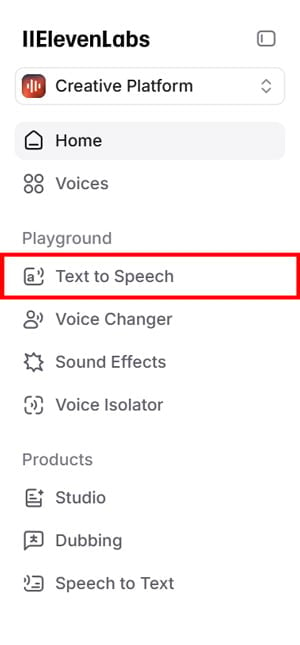
- ログイン後、左側のメニューから「Text to Speech」を選択します。
- 読み上げさせたいテキストを入力 します。
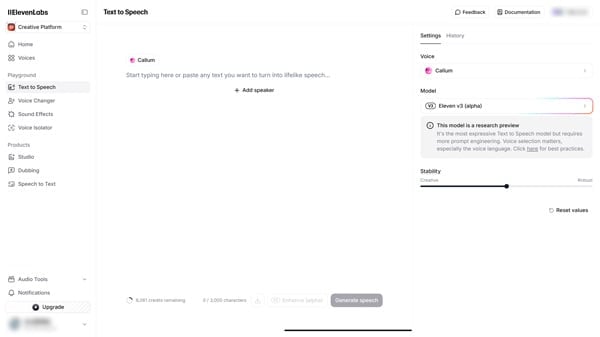
- 画面右側でボイスを選択 します。V3モデルを使用する場合は、「Best voices for V3」タグが付いたボイスを選ぶのがおすすめです。日本語プロジェクトでは、最適化が確認されるまではプリセット音声かIVCの利用が無難とされます。
ボイスの探し方: 「Japanese」と検索すると日本向けの音声がピックアップされます。今回はKyoko (京子) を使用してみました。
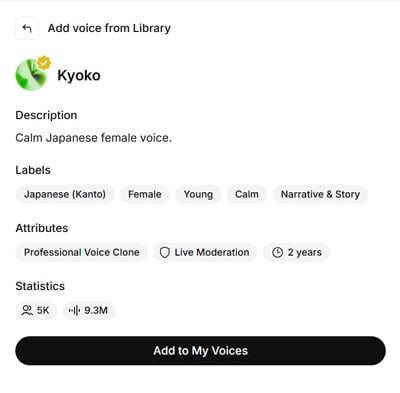
- モデルを選択 します。Eleven V3 (alpha) は特に設定なしでも抑揚があり、自然な印象を与えます。Eleven Multilingual v2と比較して格段に性能が高い印象です。
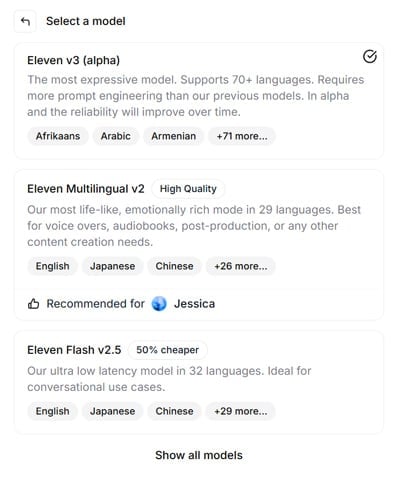
- 入力と設定が完了したら、下部にある「Generate Speech」ボタンをクリックして音声を生成します。生成された音声はダウンロードしたり、複数ある場合は選択して利用できます。
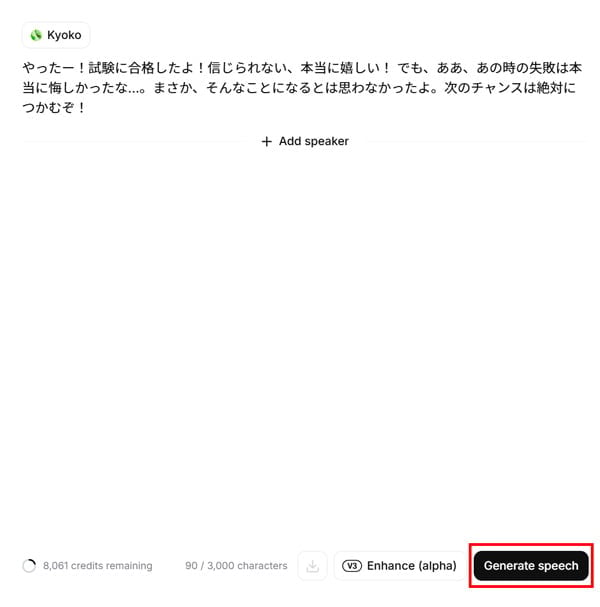
オーディオタグの活用とプロンプトエンジニアリング
Eleven v3モデルの最大の特徴であるオーディオタグを使いこなすことで、より表現豊かな音声を生成できます。

オーディオタグの記述方法
- 感情や演出を指示したい部分に、角括弧 [] で囲んだテキスト を挿入します。例: [LAUGHS], [WHISPER], [EXCITED]。
- タグは日本語でも記述可能です。例: [怒る]、[アニメ声]、[ハイテンション]。
- [whisper]のようにタグの後に続くテキスト全体に効果を適用することも可能です。
- [laughter]や[whispering]のように、タグ自体が音声として独立して生成される場合と、テキストと一緒に感情が表現される場合があります。
- 「Enhance (alpha)」機能 を押すと、AIが自動でオーディオタグを付与してくれるため、手軽に試すことができます。
オーディオタグの一覧 (例)
- 声の表情: [LAUGHS], [laughs harder], [starts laughing], [wheezing], [sigh], [exhale], [sarcastic], [curious], [excited], [dramatically], [surprised], [light chuckle], [giggles], [hysterical laughing], [big laugh], [singing]
- 声の様式: [WHISPER], [shouting], [strong accent] (例: [strong German accent])
- 効果音: [gunshot], [applause], [clapping], [explosions]
- 日本語の例: [怒る]、[落ち着いた表現]、[静かに話す]、[関西弁]、[苦笑い]、[爆笑]、[アニメ声]、[ハイテンション]
プロンプトエンジニアリングのコツ
- プロンプトの長さ: V3は250文字以上の長いプロンプトでより良い結果を出す傾向があります。
- 声とタグの一致: 落ち着いた声に怒りや叫びのタグを追加すると、矛盾した結果になることがあります。
- 少なめに試す: 多くのタグを使いすぎると、予測不能な結果になることがあります。
- テキストの工夫: 小文字を活用してテンションの高い表現にしたり、自然な会話のリズムを意識した文章構造も、AIが感情を再現する上で役立ちます。
その他の設定と機能
- 三点リーダー (…) やエムダッシュ (—) を使用すると自然な間を追加できます。
- ブレイクタグ (<break time=”1.5s”/> や [break]) を使用して、指定した長さのポーズを入れることも可能です。
強調
- 大文字化 (VERY LOUD) で単語の強調が可能です。
Stability (安定性) と Similarity (類似性) (主にV2モデル向け)
- Stability: 生成される音声の一貫性を制御します。値を下げると感情豊かになりますが、不安定になる可能性もあります。V3では主にオーディオタグで制御されます。
- Similarity: 生成される音声が元の声にどれだけ似るかを制御します。値を上げすぎると不自然になることがあります。V3では、これらの設定がほとんどなくなり、オーディオタグで主に制御されます。
- Style Exaggeration (スタイル強調): 声のスタイルの特徴 (アクセント、イントネーション、ポーズなど) を強調します。過度に設定すると不安定になる可能性があります。
Speaker Boost (スピーカーブースト)
- 合成音声と声の類似性を向上させますが、生成速度が遅くなることがあります。

実際にElevenLabsを使ってみたレビュー
ElevenLabsを実際に試用してみると、その驚くべき進化を実感できます。
サインアップはGoogleアカウントを使うとスムーズに完了しました。基本的なメニューは英語ですが、直感的な操作が可能でした。
特に印象的だったのは、Eleven v3 (alpha) の日本語読み上げ機能です。従来のEleven Multilingual v2が比較的平坦な読み上げで漢字の誤読もあったのに対し、V3は初期設定のままでも抑揚があり、非常に自然な印象でした。まるで人間の声優が読み上げているかのようなリアルさに驚かされる場面も多く、「リアルさと流暢さに驚いた」というユーザーの声も納得できます。
オーディオタグ は、想像以上に効果的でした。例えば、感情タグを挿入することで、怒り、落ち着き、ささやき、笑い、さらには関西弁やアニメ声といった幅広い表現が可能です。特に[怒る]や[アニメ声]といった日本語のタグも問題なく機能し、「Enhance (alpha)」機能を使えば自動でタグが付与される ため、手軽に試せるのも大きな利点です。
ただし、オーディオタグが不安定で無視されたり、ひどい場合はタグ自体を音声として読み上げてしまうといった報告も一部あり、現状ではまだ信頼性に欠ける面があるかもしれません。また、生成された音声が「大げさすぎるとか誇張されすぎている」と感じるユーザーもいるようで、まるで舞台役者のような話し方になる可能性も指摘されています。
Voice Design
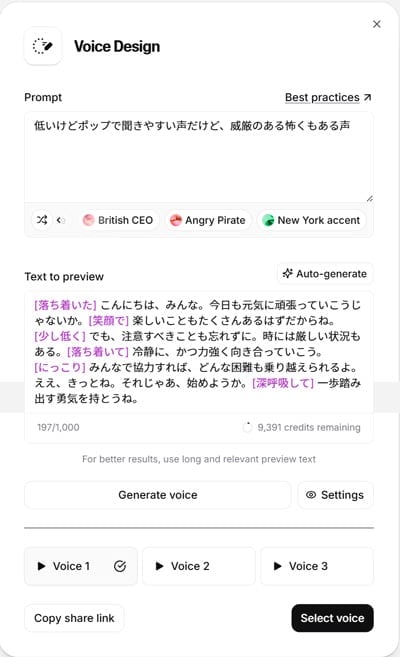
ボイスクローン や ボイスデザイン の機能も試す価値があります。特にボイスデザインでは、プロンプトで声のイメージを具体的に指定することで、独自のAI音声を作成できます。生成された声のクオリティも高く、ナレーションやキャラクターボイスとしての可能性を感じさせます。ただし、プロフェッショナルボイスクローン (PVC) については、V3向けにまだ完全に最適化されていないという問題も指摘されており、既存の日本語PVCを使うと音声が歪んだり不自然になったりするケースもあるようです。
マルチスピーカーダイアログ機能
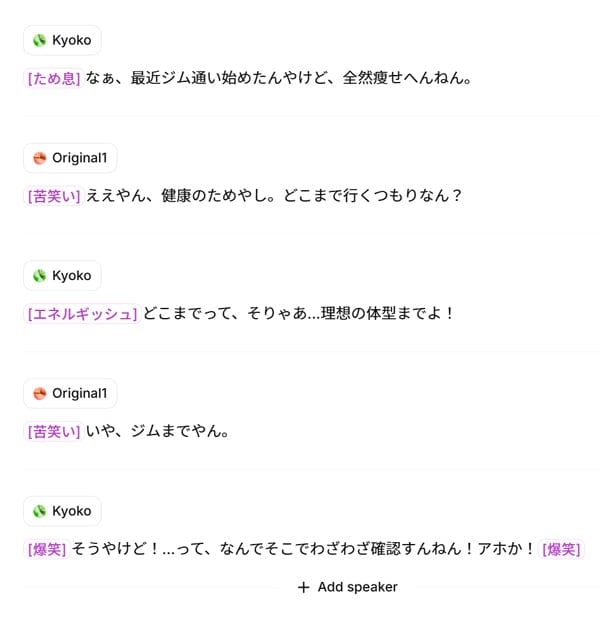
マルチスピーカーダイアログ機能では、複数のボイスを割り当てることで、自然な会話形式のコンテンツが作成できる点も魅力的です。関西弁のコントをAIが演じ分け、さらに[苦笑い]や[爆笑]といったタグで笑い声まで表現できるのには驚かされました。
全体的には、無料版でもデモ音声を試聴でき、その高い精度は簡単なナレーションや説明動画であれば十分に活用できるレベルです。しかし、日本語の品質については「ネイティブとは似ても似つかない」「観光客がネイティブの話し方を真似しようとしているようだ」といった厳しい意見もあり、日本語特有のピッチアクセントの複雑さや敬語の使い分け、文化的な感情表現のニュアンス などが、AIにとって依然として高い壁となっていることは明らかです。
AI音声技術が切り拓く新たなコンテンツ制作の未来
ElevenLabs (イレブンラボ) の最新モデルEleven v3 (alpha) は、AI音声合成の表現力において大きな可能性を秘めている と言えます。特にその日本語対応の向上 と、オーディオタグによる細やかな感情表現の指示 は、コンテンツクリエイターにとって画期的な機能です。まるでAIに「演出家」として指示を出すように音声をディレクションできる点は、私たちとAIとの関わり方を大きく変える可能性を秘めています。
現在のアルファ版の段階では、日本語のリアルさ、オーディオタグの安定性、そしてカスタム音声 (PVC) の品質にはまだ課題が残されており、ユーザー側にもプロンプトエンジニアリングのスキルが求められます。しかし、これらの限界を理解し、試行錯誤を重ねることで、これまでにない高品質で感情豊かなAI音声コンテンツを制作できる ことは間違いありません。
Eleven v3 (alpha) は、AI音声合成の最前線を体験する良い機会となるでしょう。今後、さらに技術が進化し、より自然で多様な日本語表現が可能になることで、動画、ポッドキャスト、オーディオブック、ゲーム、さらにはAIキャラクターとのインタラクションなど、あらゆるコンテンツ制作の可能性が飛躍的に広がる と期待されます。AIが感情を込めて「演じる」時代が、すぐそこまで来ているのかもしれません。

みんなのらくらくマガジン 編集長 / 悟知(Satoshi)
SEOとAIの専門家。ガジェット/ゲーム/都市伝説好き。元バンドマン(作詞作曲)。SEO会社やEC運用の経験を活かし、「らくらく」をテーマに執筆。社内AI運用管理も担当。
