Google TurboQuant Explained: How the New AI Memory Algorithm Slashes Costs and Disrupts Semiconductor Stocks
[This article may contain PR]

Key Takeaways
- What it is: Google TurboQuant is a groundbreaking, open-source data compression algorithm released in March 2026 that solves the physical memory limits of AI.
- Performance Leap: It compresses the temporary memory (KV cache) of Large Language Models (LLMs) to 1/6 of its original size and accelerates processing speeds by up to 8x.
- Zero Precision Loss: By utilizing mathematical approaches like PolarQuant and QJL, TurboQuant achieves extreme compression without causing AI hallucinations or any drop in intelligence.
- Market Disruption: The announcement caused semiconductor stocks like Micron to drop, as the industry shifts from relying on expensive hardware upgrades to highly efficient software optimization.

- What is Google TurboQuant? The AI Memory Revolution
- How TurboQuant Works: Achieving Zero-Loss Compression
- 1. PolarQuant (Coordinate Transformation)
- 2. QJL (Quantized Johnson-Lindenstrauss)
- Flawless Performance in the "Needle In A Haystack" Test
- Why Did TurboQuant Cause Semiconductor Stocks to Drop?
- What This Means for Consumers: AI Pricing and Hardware Costs
What is Google TurboQuant? The AI Memory Revolution

(Source: Google Research)
Have you ever wished your AI could instantly process entire textbooks or run heavy applications seamlessly on your smartphone? In March 2026, Google Research unveiled a game-changing technology called TurboQuant, an open-source software algorithm designed to drastically reduce AI memory consumption.
Currently, high-performance Large Language Models (LLMs) like ChatGPT and Gemini consume massive amounts of temporary memory known as the “KV (Key-Value) cache”. As an AI processes longer texts or retains extensive conversational history, this KV cache swells to gigabytes, eventually hitting a physical “memory wall”.
TurboQuant directly solves this bottleneck. It is a software-based optimization that integrates directly into existing systems without requiring AI model retraining, effectively cutting memory usage by up to a sixth while making information retrieval eight times faster.

How TurboQuant Works: Achieving Zero-Loss Compression
(Source: Google Research)
Historically, memory-saving approaches like “SnapKV” forced AI to forget older or seemingly unimportant data. However, this led to “amnesia” and hallucinations, where the AI would lose track of crucial context and provide irrelevant answers.
TurboQuant discards absolutely nothing. It achieves “extreme compression with zero degradation” through a two-step mathematical approach:
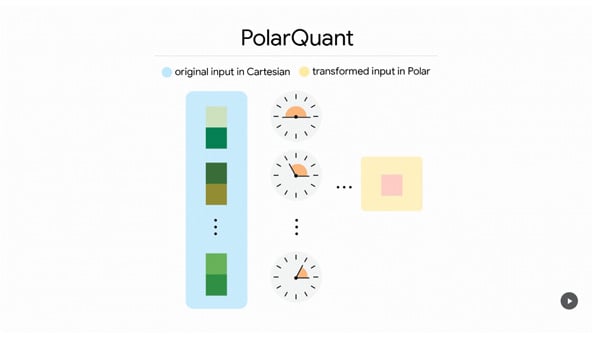
1. PolarQuant (Coordinate Transformation)
Traditionally, AI data is stored in a Cartesian coordinate system (X and Y axes). PolarQuant rotates and transforms this data into “Polar coordinates” (angles and radii). This allows complex data to fit neatly into a regular circular grid, compressing vast amounts of information instantly without any memory overhead.
2. QJL (Quantized Johnson-Lindenstrauss)
Extreme compression inherently leaves minor mathematical errors, which can bias an AI’s attention score (how it measures the importance of information). To fix this, TurboQuant uses the QJL algorithm, applying a mere “1-bit filter” (+1 or -1 sign bit) to perfectly correct these residual errors. This neutralizes any bias and restores the AI’s accuracy to 100%.
Flawless Performance in the “Needle In A Haystack” Test
The ultimate proof of TurboQuant’s capability is its performance in the “Needle In A Haystack” test. When tasked with finding a single, unrelated password (the needle) hidden within over 100,000 words of text (the haystack), TurboQuant achieved a 100% perfect accuracy rate with zero misses, all while running on a fraction of the memory.
Table: Traditional AI vs. AI with TurboQuant
| Feature | Traditional AI (No Compression) | With TurboQuant |
|---|---|---|
| Memory Usage | Extremely high (hits limits quickly) | Reduced up to 1/6 |
| Processing Speed | Slow due to heavy memory I/O | Up to 8x faster |
| Answer Quality | High | Zero degradation (100% maintained) |
| Operating Environment | Requires expensive data centers | Runs smoothly on standard PCs/Smartphones |
| Infrastructure Cost | Demands massive hardware investments | Expands capacity on existing hardware |

Why Did TurboQuant Cause Semiconductor Stocks to Drop?

Immediately following Google’s publication of the TurboQuant research, the financial markets experienced a shockwave. Stock prices for major physical memory vendors, such as Micron and Western Digital, experienced a sudden drop.
Historically, AI advancements have been a tailwind for semiconductor manufacturers. So, why the reverse effect this time? The answer lies in the shift from hardware dependency to software efficiency. TurboQuant is fundamentally a “software revolution that cannibalizes hardware sales”.
If AI companies can effectively multiply their existing memory capacity by 6x simply by deploying TurboQuant, they will likely scale back on multi-trillion-dollar physical memory expansion plans. This signals a critical turning point: the power dynamic and pricing authority in the AI ecosystem are shifting from hardware manufacturers selling expensive components to software researchers developing efficient algorithms. Conversely, cloud providers like AWS (Amazon) and Azure (Microsoft) are projected to see massive margin boosters, as they can now host significantly more AI clients on their existing server racks.

What This Means for Consumers: AI Pricing and Hardware Costs
Will PC hardware and GPU prices plummet tomorrow? Not immediately. TurboQuant primarily optimizes large-scale AI servers in data centers.
However, in the long term, the extreme price inflation caused by the “AI hardware boom” is expected to stabilize. The industry is moving away from the “brute force” method of blindly buying high-end GPUs and massive RAM. As software optimization takes over, hardware supply shortages will ease.
For the everyday user, TurboQuant brings three major benefits:
- Lower AI Subscription Costs: As operational costs for AI companies plummet, we can expect cheaper subscription plans and expanded free tiers for consumer AI tools.
- The Rise of Local AI: Highly compressed, ultra-smart AI will soon run natively and securely on our personal smartphones and laptops without relying on the cloud.
- Powerful AI Agents: The reduced memory cost will make it financially viable to deploy teams of autonomous “AI Agents” that can simultaneously research and execute complex tasks on our behalf.
The evolution of AI has officially transitioned from brute force to smart efficiency. By staying informed about technologies like TurboQuant and experimenting with new tools, users can fully leverage the next generation of highly accessible, lightning-fast AI.


What is Cerebras Systems? The Wafer-Scale AI Chip Challenging NVIDIA’s Inference Dominance

What is Physical AI? The 2026 Trend That Will Revolutionize Robotics and Daily Life

Rapidus Explained: Japan’s Bold $35B Bet on 2nm Chips to Rival TSMC

Can Former PlayStation Engineers Dethrone NVIDIA? Meet the Japanese AI Chip Slashing Power Use by 90%

The AI Chip War: Can Google’s TPU Overthrow NVIDIA’s GPU Dominance with a Cost Revolution?

Google Mixboard: Visualize Ideas Fast with Nano Banana
On the lifestyle web magazine "Minna no Rakuraku Magazine",
we update useful tips and deals every month. Please bookmark us!
- EXPO2025 Futures Complete Guide: 2026 Dates, Tickets & Drone Show Revival in Osaka
- The Ultimate Guide to Instagram Plus: New Features, Pricing, and Stealth Story Views Explained